
Modelling sample selection using Archimedean copulas M D. S
Econometrics Journal (2003), volume 6, pp. 99–123.
Modelling sample selection using Archimedean copulas
M URRAY D. S MITH
Econometrics and Business Statistics, School of Economics and Political Science, Faculty of
Economics and Business, University of Sydney, Sydney NSW 2006, Australia
E-mail: Murray.Smith@econ.usyd.edu.au
Received: February 2002
Summary By a theorem due to Sklar, a multivariate distribution can be represented in terms
of its underlying margins by binding them together using a copula function. By exploiting
this representation, the ‘copula approach’ to modelling proceeds by specifying distributions
for each margin and a copula function. In this paper, a number of families of copula functions
are given, with attention focusing on those that fall within the Archimedean class. Members
of this class of copulas are shown to be rich in various distributional attributes that are desired
when modelling. The paper then proceeds by applying the copula approach to construct models for data that may suffer from selectivity bias. The models examined are the self-selection
model, the switching regime model and the double-selection model. It is shown that when
models are constructed using copulas from the Archimedean class, the resulting expressions
for the log-likelihood and score facilitate maximum likelihood estimation. The literature on
selectivity modelling is almost exclusively based on multivariate normal specifications. The
copula approach permits selection modelling based on multivariate non-normality. Examples
of self-selection models for labour supply and for duration of hospitalization illustrate the
application of the copula approach to modelling.
Keywords: Selectivity, Self-selection model, Switching regimes model, Double-selection
model, Copula, Sklar’s theorem, Copula representation, Copula approach, Families of copulas, Archimedean, Kendall’s τ .
1. INTRODUCTION
This article sets out to demonstrate the application of the ‘copula approach’ to model specification in the context of binary models designed to account for data selectivity, should it be
present. The binary models in question have had a long history of use in modelling selectivity in
microeconometrics. The self-selection model discussed in Sections 3 and 4. In Section 5, attention focuses on the application of the copula approach to higher-dimensional sample selection
models, such as the switching regimes model and the double-selection model.
Over the last 30 to 40 years, a large volume of literature on each of the aforementioned sample selection models has been built up in economics and econometrics; see, for example, Vella
(1998) for a recent survey. However, the vast majority of analyses have depended on the statistical
assumption of multivariate normality. Although ubiquitous throughout all facets of econometric
modelling, the adequacy of inference based on the assumption of multivariate normality has often
been questioned, and has often found to be wanting in the context of sample selection models.
Unfortunately, relaxing multivariate normality by replacing it with an alternative multivariate
c Royal Economic Society 2003. Published by Blackwell Publishing Ltd, 9600 Garsington Road, Oxford OX4 2DQ, UK and 350 Main
Street, Malden, MA, 02148, USA.
100
Murray D. Smith
distribution has received relatively little attention. In the main, this was because of the additional
computational burdens that were expected to arise. Instead, the literature developed by focusing
on semi-parametric and non-parametric versions of these models, where modelling improvements might be brought about by the use of flexible functions of parameters and the covariates of
the random variables; see, for example, the articles in the special edition by H¨ardle and Manski
(1993). The aim of this article is to return to the issue of replacing multivariate normality with
an alternative multivariate distribution (or, more precisely, a class of multivariate distributions).
The adverse computational consequences are, if anything, mitigated under the proposed method
of model specification: the so-called copula approach.
The copula approach is a modelling strategy whereby a joint distribution is induced by specifying marginal distributions, and a function that binds them together: the copula. The copula
parameterizes the dependence structure of the random variables, thereby capturing all of the
joint behaviour. This then frees the location and scale structures to be parameterized through the
margins, one at a time. Most importantly, the copula approach permits specifications other than
multivariate normality, although it does retain that distribution as a special case.
The copula approach is a relatively new method to economics and econometrics, with a small,
but growing pedigree. For example, Bouy´e et al. (2000) demonstrate applications of copulas to
models relevant to finance, paying particular attention to a number of estimation methods other
than maximum likelihood. In a time series context, Patton (2001) uses copulas conditioned on
past information to model exchange rates. Dardanoni and Lambert (2001) exploit the monotonicity properties (stochastic ordering) of bivariate copulas (in their case used to represent the joint
distribution of a country’s pre- and post-tax living standards) to perform paired cross-country
comparisons. The specification method suggested by Lee (1983) for modelling self-selection
provides an example of the copula approach, as will be shown in what follows.
As all multivariate distributions have a copula representation (Sklar’s theorem; see
Section 2), it might seem that the copula approach is nothing more than the reworking of an old
theme. Might the advantage derived by the copula approach simply be that econometricians are
better practiced at modelling univariate distributions than they are multivariate ones? The ideal,
of course, is to choose the right statistical model a priori , and hence the right copula. However,
when working with empirical data it is rare to have such insight. The specification problem is
further compounded in most sample selection models due to latency of the underlying utilitarian
variables, and the presence of covariates. When faced with such difficulties, it is advantageous to
have at hand a range of potential candidate models from which a preferred fit can emerge. Under
a copula approach, families of models can be constructed according to classes of copula functions: of particular interest here is the class of Archimedean copulas. Archimedean copulas can
display a range of distributional behaviour such as joint asymmetry, excess joint skewness and
joint kurtosis. When applied in the specification of selectivity models, relatively simple formulae
for likelihood and score functions result, thereby facilitating estimation by maximum likelihood
(ML hereafter). In Section 2, the basic elements of copula theory are presented, including those
for the class of Archimedean copulas.
In Section 4, two examples are presented of self-selection models. These relate to labour
supply and to duration of hospitalization, utilizing data from previous studies. The marginal
models in each example are parameterized according to the specification preferred by previous
authors, enabling attention to focus on the fit achieved by various copulas. In this article, standard information criteria (e.g. AIC and BIC) are used for copula choice as the members of the
Archimedean class are, in general, parametrically non-nested. Fortunately, due to fixity of the
margins, the number of parameters does not vary across estimated models, so that the aforec Royal Economic Society 2003
Modelling sample selection
101
mentioned information criteria are equivalent to choice based on the maximized value of the
log-likelihood function. In this article, model selection is an a posteriori consideration, focusing
on selection after estimation.
2. COPULA THEORY
2.1. Sklar’s theorem
With a view to the main result that is embodied in Sklar’s theorem, the copula for an n-dimensional multivariate distribution function F with given one-dimensional marginal distribution
functions F1 , . . . , Fn , is the function that binds together the margins in such a manner as to
form precisely the joint distribution function. The action performed by the copula implies that
it serves to represent the dependence characteristics that associate each of the underlying random variables, irrespective of the form the margins take. Yet another perspective on the copula
function concerns its close links to the multivariate uniform distribution (with margins that are
standard uniform); in fact, in this case the copula is equivalent to the joint distribution. Thus, one
use of copulas is in simulation (e.g. Clemen and Reilly (1999)).
To date, most uses of copula theory have concentrated on the study of the association between
random variables and, to a slightly lesser extent, the establishment of limiting (Fr´echet) bounds
on distributions. For details on the origins, evolution and properties of copula models and related
properties see Dall’Aglio (1991), Schweizer (1991) and Nelsen (1999).
The main result of interest here is a theorem due to Sklar (given in the following for the
bivariate case). Sklar’s theorem shows that there exists a copula function which acts to represent
the joint cdf of random variables in terms of its underlying one-dimensional margins. Let the
margins F1 (x1 ) and F2 (x2 ) denote, respectively, the cumulative distribution functions (cdf) of
the random variables X 1 and X 2 ; that is, Fi (xi ) = Pr(X i ≤ xi ), where xi ∈ R (i = 1, 2; R
denotes the extended real line R ∪ {−∞, +∞}), and let F(x1 , x2 ) = Pr(X 1 ≤ x1 , X 2 ≤ x2 )
denote the joint cdf. Then, for some two-place function C, the joint cdf has the representation
(e.g. Nelsen (1999, Theorem 2.3.3))
F(x1 , x2 ) = C(F1 (x1 ), F2 (x2 ))
(1)
where C is termed the copula function. The copula representation is a re-formulation of the joint
cdf that separates the margins F1 and F2 from their interaction. So while the copula function takes
as arguments the margins F1 and F2 in the representation (1), the function itself is independent
of those margins. The copula serves to capture the dependence characteristics that exist between
the random variables X 1 and X 2 . Nelsen (1999, Section 2.3) provides a proof of (1) that follows
the method given in Schweizer and Sklar (1983, Ch. 6) (where the multivariate version of the
theorem is proved).
2
If F1 and F2 are continuous functions, then (1) is unique for any (x1 , x2 ) ∈ R . On the other
hand, if either or both X 1 and X 2 are discrete random variables that take values on some lattice
of points , then (1) is unique provided (x1 , x2 ) ∈ , but not elsewhere; this does not cause any
great harm, since the region outside of the supporting lattice is rarely of interest. Implicit in (1) is
C(u, v) = 0 if either or both u and v are zero, and C(1, v) = v and C(u, 1) = u, where the pair
(u, v) ∈ I2 (I denotes the closed interval [0, 1] of the real line). Other terminology for the copula
includes ‘uniform representation’ (Kimeldorf and Sampson, 1975), and ‘dependence function’
(Galambos, 1978); in the mathematics literature, the copula is termed the ‘t-norm’.
c Royal Economic Society 2003
102
Murray D. Smith
2.2. Examples of copulas
Three bivariate copulas of some importance are
5 = uv,
(2)
u + v − 1 + |u + v − 1|
2
= max(u + v − 1, 0),
(3)
u + v − |u − v|
2
= min(u, v),
(4)
W=
and
M=
where (u, v) ∈ I2 . 5 is termed the Product copula, and it corresponds to stochastic independence;
that is, if two random variables are independent, then 5 is the copula of their joint distribution.
W is termed the Fr´echet lower bound for copulas, and M the Fr´echet upper bound for copulas.
The closed interval [W, M] has the property of containing all bivariate copulas; namely, for all
copulas C on I2 :
W ≤ C ≤ M.
(5)
These bounds—the Fr´echet bounds for copulas—were obtained by Hoeffding, and they arise as a
consequence of applying the representation (1) to the Fr´echet bounds for (bivariate) distributions:
max(F1 (x1 ) + F2 (x2 ) − 1, 0) ≤ F(x1 , x2 ) ≤ min(F1 (x1 ), F2 (x2 ))
2
((x1 , x2 ) ∈ R )
(e.g. Kwerel (1983)). One use of the Fr´echet bounds for copulas of some implication for statistical modelling is in establishing the coverage of a given family of copulas. For further discussion
see, for example, Fisher (1997).
2.3. Families of copulas
For the purposes of statistical modelling it is desirable to parameterize the copula function so
that data can be used to shed light on the extent of association between the random variables
of interest. Let θ denote the association parameter of the bivariate distribution (possibly vector
valued) and write the parameterized copula as per
Cθ (u, v).
This notation denotes a family of copulas, where the members are indexed according to values
assigned to θ. Provided that the margins F1 and F2 do not depend on θ, the representation (1)
holds for all members of a given family; this assumption is imposed hereafter.
There are numerous examples of families of bivariate copulas given in Joe (1997) and Nelsen
(1999). For example, the family of Bivariate Normal copulas is given by
Cθ (u, v) = 82 (8−1 (u), 8−1 (v); θ )
where − 1 ≤ θ ≤ 1.
(6)
c Royal Economic Society 2003
103
Modelling sample selection
Here, 8(·) denotes the cdf of a standard normal variate, and 82 (·, ·; θ ) the cdf of a bivariate standard normal variate with Pearson’s product moment correlation coefficient θ. Note that setting
u = 8(x1 ) and v = 8(x2 ) in (6) recovers the bivariate standard normal cdf. This family is the
basis of Lee’s self-selection model described in Section 3.3.1. The Farlie–Gumbel–Morgenstern
family of copulas (FGM hereafter) is given by
Cθ (u, v) = uv(1 + θ(1 − u)(1 − v))
where − 1 ≤ θ ≤ 1.
(7)
The FGM family can be useful in analytic work due to its mathematical simplicity; in Section 3.3.2 it is used to construct the FGM self-selection model. The Plackett family of copulas is
given by
p
where θ > 0, θ 6= 1 and
1 s − s 2 − 4uvθ (θ − 1)
2(θ−1)
s = 1 + (u + v)(θ − 1),
Cθ (u, v) =
(8)
uv
when θ = 1.
Lee and Maddala employ the Plackett family in their discussion of joint and sequential decision
rules (see Maddala (1994, Ch. 21)).
The ability of a given family of copulas to represent differing degrees of association can be
examined in terms of the extent to which it covers the interval between the lower and upper
Fr´echet bounds for copulas (5). This is generally determined at the extremes of the parameter
space for θ. For example, for the Bivariate Normal family (6), C−1 (u, v) = W and C1 (u, v) =
M, so that this family has full coverage: Cθ (u, v) ∈ [W, M]. Furthermore, the family of Bivariate
Normal copulas is said to be comprehensive, where this nomenclature means that a given family
includes W , M and 5 amongst its members, or as limiting cases. The Plackett family is comprehensive too, for under (8), limθ→0+ Cθ (u, v) = W and limθ →∞ Cθ (u, v) = M. Comprehensive
families of copulas therefore parameterize the full range of association and, by (1), this property
holds irrespective of the form of the margins. However, there are typically many other features
of the data that are of interest, and these may not necessarily be well modelled if attention is
restricted to using comprehensive families of copulas.
There are many copula families that are not comprehensive, one example is the FGM
family (7): it includes 5, but not W and M. For such families it is desirable to assess coverage in terms of measures of association. The most familiar measure is Pearson’s product moment
correlation coefficient, but due to its lack of invariance with respect to the margins, the properties of this measure are dominated by others such as Kendall’s τ and Spearman’s ρ (Joe, 1997,
Section 2.1.9). The latter two are concordance measures that are bounded between [−1, 1]: both
are equal to −1 at W , 1 at M and 0 for 5. Importantly, both measures are invariant to strictly
increasing transformations of the variables, implying that they depend only on the copula of the
joint distribution, and not the margins. For independent pairs (X 1i , X 2i ), i = 1, 2, 3, that are
copies of (X 1 , X 2 ), τ and ρ are defined as
τ = Pr((X 11 − X 12 )(X 21 − X 22 ) > 0) − Pr((X 11 − X 12 )(X 21 − X 22 ) < 0)
and
ρ = 3(Pr((X 11 − X 12 )(X 21 − X 23 ) > 0) − Pr((X 11 − X 12 )(X 21 − X 23 ) < 0)).
Should (X 1 , X 2 ) be a pair of continuous random variables, with the copula of their joint distribution given by C, then τ and ρ may be simplified:
c Royal Economic Society 2003
104
Murray D. Smith
τ =4
Z Z
I2
C(u, v)dC(u, v) − 1
= 4E[C(U, V )] − 1
and
ρ = 12
Z Z
I2
uvdC(u, v) − 3
= 12E[U V ] − 3.
Here, U and V denote standard uniform random variables with joint cdf C. For the FGM family
of copulas τ = 2θ/9 and ρ = θ/3, clearly −2/9 ≤ τ ≤ 2/9 and −1/3 ≤ ρ ≤ 1/3 for this
family. For detailed derivations of the above results see Nelsen (1999, Section 5.1).
2.4. The Archimedean class of copulas
Of particular importance in this article is the class of Archimedean copulas. The class encompasses many families of copulas, a number of which can be of use in statistical modelling. The
mathematical properties of the Archimedean class are captured by an additive generator function
ϕ : I → [0, ∞], which is a continuous, convex, decreasing function (ϕ 0 (t) < 0 and ϕ 00 (t) > 0,
for 0 < t < 1), with terminal ϕ(1) = 0. ϕ may also be indexed by the association parameter θ,
thus an entire family of copulas can be Archimedean. Any function ϕ that satisfies these conditions can be used to generate a valid bivariate cdf. The advantage in mathematics of working with
Archimedean copulas is the achievement of reduction in dimensionality: while the copula of an
n-variate distribution is an n-place function, the generator ϕ only ever takes a single argument.
In econometrics, this property of Archimedean copulas has the potential to be of use in models of limited dependent variables, especially those requiring some probabilistic enumeration on
high-dimensional subspaces, for evaluation then becomes essentially a univariate task.
In the bivariate case, the means by which ϕ generates the copula is according to
ϕ(C(u, v)) = ϕ(u) + ϕ(v).
(9)
Note that the generator is unique up to a scaling constant. Particular examples are ϕ(t) = − log t
and ϕ(t) = (t −θ − 1)/θ, which are, respectively, the generators of the Product copula 5 and the
Clayton family of copulas
Cθ (u, v) = (u −θ + v −θ − 1)−1/θ
where θ ≥ 0.
(10)
Note that neither the Bivariate Normal family, nor the Plackett and FGM families are members
of the Archimedean class. Examples of families of Archimedean copulas are listed in Table 1.
If the terminal ϕ(0) = ∞, the generator is termed strict, and the inverse function ϕ −1 exists.
The generators of 5, (10) and those listed in Table 1 are strict. In this instance, from (9), the
copula is recovered by
C(u, v) = ϕ −1 (ϕ(u) + ϕ(v)).
Non-strict generators are those for which ϕ(0) < ∞; in this case, the generators are said to
have a singular component. Analysis in this instance must begin by defining a pseudo-inverse
function, ϕ [−1] . An example is ϕ(t) = 1 − t, for which ϕ [−1] (t) = max(1 − t, 0): note that
c Royal Economic Society 2003
105
Modelling sample selection
Table 1. Examples of families of bivariate Archimedean copulas.
Name
Copula Cθ (u, v)
AMH
uv/(1 − θ(1 − u)(1 − v))
p
1 r + r 2 + 4θ ,
2
AP
Parameter space
Generator ϕ(t)
Kendall’s τ
−1 ≤ θ < 1
log 1−θ (1−t)
t
−0.1817 ≤ τ < 13
0<θ <∞
(1 + θ/t)(1 − t)
0≤θ <∞
1 −θ − 1)
θ (t
−1 < τ < 13
0≤τ <1
−∞ < θ < ∞
−θt
− log e −θ −1
−1 < τ < 1
1≤θ <∞
(− log t)θ
0≤τ <1
1≤θ <∞
− log(1 − (1 − t)θ )
0≤τ <1
where r = u + v − 1 − θ u1 + v1 − 1
Clayton (u −θ + v −θ − 1)−1/θ
Frank
−θ −1 log(1 + (e−θu − 1)(e−θ v − 1)/
(e−θ − 1))
Gumbel exp(−((− log u)θ + (− log v)θ )1/θ )
Joe
1 − ((1 − u)θ + (1 − v)θ − (1 − u)θ (1 − v)θ )1/θ
e
−1
Notes: AMH denotes Ali–Mikhail–Haq.
ϕ [−1] (ϕ(u) + ϕ(v)) = max(u + v − 1, 0) = W , thus the lower Fr´echet bound for (bivariate)
copulas is Archimedean. In a modelling context it is not entirely clear what gains might be
made by specifying non-strict generators, so in this article attention is confined to the category
of strict generators. Nelsen (1999, Ch. 4) gives extensive details about Archimedean copulas
(strict and non-strict); see also Genest and MacKay (1986), Genest and Rivet (1993), Jouini and
Clemen (1996) and Mari and Kotz (2001, Section 4.6). A recent application of Archimedean
copulas in finance appears in Henessey and Lapan (2002), they study optimal allocation rules
for portfolios of risky assets. In actuarial science, Valdez (2001) uses Archimedean copulas to
induce dependence amongst random variables, where it is the distribution of the sum that is of
interest (in Valdez’s case the sum represents total claims made against an insurer).
To illustrate the range of bivariate behaviour that can be represented by Archimedean copulas,
consider Figure 1. Each plot shows the contours of a bivariate probability density function (pdf)
where, for reasons due only to familiarity, both margins are standard normal. The top left plot
depicts the well-known elliptical contours of the bivariate standard normal pdf, with Pearson
product moment correlation coefficient θ = 0.7. All plots (apart from the AMH) calibrate to
τ = 0.5, where, for an Archimedean copula with generator ϕ,
τ =1+4
1
Z
0
ϕ(t)
dt
ϕ 0 (t)
with notation ϕ 0 (t) = ∂t∂ ϕ(t); for a proof of this result see Nelsen (1999, p. 130). For example, for the Clayton family (10), τ = θ/(θ + 2), so that this family covers 0 ≤ τ < 1. The
distributions generated by Archimedean copulas evidence a wide range of behaviour including
joint asymmetry and skewness, and fat and thin tails in comparison to the bivariate normal.
Amongst the contours generated by Archimedean copulas, only the Frank shows (radial) symmetry (see Nelsen (1999, Section 2.7) for a discussion of the concepts of symmetry in bivariate
distributions), although by reducing τ towards zero in each plot, the resulting contour plots would
all start to appear increasingly circular. Relative to the bivariate normal, the contours generated
by the Clayton and Joe copulas imply fat tailed distributions, as do those of the Frank and Gumbel but to a lesser extent. Contours of thin tailed distributions can be seen in each of the Clayton,
Gumbel and Joe plots. The wide range of distributional shapes that the Archimedean copulas can
depict is an indicator that members of this class may be useful in modelling. In terms of coverage,
c Royal Economic Society 2003
106
Murray D. Smith
= 0.7
Bivariate Normal,
2
AMH,
= 0.714 ( = 0.2)
2
1
1
0
0
-1
-1
-2
-2
-2
-1
0
Clayton,
2
1
2
=2
-2
-1
0
1
0
0
-1
-1
-2
2
= 5.74
Frank,
2
1
1
-2
-2
-1
0
Gumbel,
2
1
2
=2
-2
-1
0
Joe,
2
1
1
0
0
-1
-1
-2
1
2
1
2
= 2.86
-2
-2
-1
0
1
2
-2
-1
0
Figure 1. Bivariate pdf contour plots induced by copula, N (0, 1) margins (τ = 0.5).
only the Frank family is comprehensive. The last column of Table 1 sets down the coverage of
the family in terms of the bounds applicable to their respective τ measure.
Finally, a particular result for Archimedean copulas that is especially relevant in this article:
∂
ϕ 0 (v)
Cθ (u, v) = 0
.
∂v
ϕ (Cθ (u, v))
(11)
c Royal Economic Society 2003
Modelling sample selection
107
This result follows from (9): simply differentiate both sides of that equation with respect to v and
re-arrange the result. Since ϕ is convex and decreasing on I, and Cθ (u, v) < Cθ (1, v) = v for
(u, v) ∈ (0, 1)2 , it follows that (11) takes values in (0, 1).
2.5. The copula approach to model construction
For the purposes of statistical modelling, it is the converse of the copula representation of the
joint cdf given by Sklar’s theorem that is relevant. In other words, given models for the margins
and a copula function that binds them together, this then has the effect of constructing a statistical
model for the random variables of interest, as a joint cdf is specified. Consider, for example, a
bivariate setting in which X 1 and X 2 denote the variables of interest. Required is a statistical
model for the true, but unknown joint distribution of X 1 and X 2 ; naturally, this distribution may
depend on parameters and covariates. Under a copula approach, models for the margins F1 (x1 )
and F2 (x2 ) are proposed, as well as a selection of a copula family Cθ . Then, by (1), these selections have the effect of specifying the joint cdf of X 1 and X 2 . Intuitively, the copula approach
determines each component of the overall model, then engineers them together using a copula
function.
As would be expected, the copula approach does not necessarily guarantee unique identification of the parameters of the resulting model. That issue would need to be addressed on a case
by case basis. An example in which parameter identification is important appears in Section 5.1,
where the switching regimes model is discussed.
The use of the copula in statistical modelling is beginning to expand into areas such as economics and econometrics; perhaps the most accessible contribution to date being a series of five
studies reported in Joe (1997, Ch. 11) that estimate copula models for various multivariate and
longitudinal data sets. An added boon for modelling that results by adopting a copula approach
concerns the freedom to specify each margin; for example, identicality in distribution of the margins need not be imposed. Indeed, because the copula representation is unique on the domain
of support of the random variables in question, multivariate models can be constructed using a
copula approach whose margins can be either continuous or discrete, or mixtures of both.
In the following two sections, examples are given of the copula approach applied in the
context of the classic self-selection model of microeconometrics.
3. THE SELF-SELECTION MODEL
3.1. Model and likelihood
Sample stratification, or sample selection, is commonplace amongst microeconometric data,
whereby underlying individual choices can themselves influence the observations collected on
the random variables of interest. Models of increasing complexity have been constructed to
account for stratification in its various guises, should it be present, and a number of these are discussed in texts such as Amemiya (1985, Sections 10.6–10.10), Maddala (1983), Maddala (1994,
Part III), and Lee (1996, Section 5.6). In this section, attention focuses on the self-selection model
based on a binary indicator S that governs whether or not an observation is generated on a second random variable Y . In economics, one often-studied example of this type of self-selectivity is
c Royal Economic Society 2003
108
Murray D. Smith
labour force participation, where data generated on labour supply from non-participants is unable
to reflect their true market wage.
Typically, the self-selection model is embedded within an utilitarian framework according to
a pair of underlying latent random variables Y1∗ and Y2∗ ; selectivity arises if these unobservables
are mutually dependent. Here it is assumed that the cdf of Yi∗ (i = 1, 2), denoted by Fi (yi∗ ) =
Pr(Yi∗ ≤ yi∗ ), where yi∗ ∈ R, depends on the linear function xi0 βi and a scaling factor σi , where
X i = xi (ki × 1) is a vector of covariates of Yi∗ , and βi (ki × 1) and scalar σi are unknown
parameters. The joint cdf of (Y1∗ , Y2∗ ) is denoted by F(y1∗ , y2∗ ) = Pr(Y1∗ ≤ y1∗ , Y2∗ ≤ y2∗ ), and it
depends on all covariates and parameters.
The purpose of Y1∗ is to represent participation. In the examples that follow, Y1∗ is assumed
to be a continuous random variable; however, this can be relaxed without loss of generality. In
the self-selection model, Y2∗ is observed for participants. In this section, it is assumed that Y2∗ is
a continuous random variable with pdf f 2 (y) = ∂∂y F2 (y), for all real y in the support of Y2∗ .
The self-selection model arises when observations on a pair of random variables (S, Y ) are
generated according to the following observation rules:
S = 1{Y1∗ > 0}
and
Y = 1{Y1∗ > 0}Y2∗
where 1{A} denotes the indicator function, taking value 1 if event A holds, and 0 otherwise. In
effect, Y2∗ can be observed only when Y1∗ > 0. The participation mechanism is represented by
the Bernoulli variable S, and it derives its properties from those of Y1∗ . Note that when S = 0,
Y2∗ cannot be observed, and Y is assigned a dummy value of 0.
Let s1 , . . . , sn denote n observations generated on S(s j ∈ {0, 1}, j = 1, . . . , n), and y1 , . . . ,
yn the corresponding n observations generated on Y (y j ∈ R, j = 1, . . . , n). For a random sample of n observations, the likelihood function for the self-selection model is given by
(cf. Amemiya (1985, equation (10.7.3)))
Y
Y
L=
Pr(Y1∗j ≤ 0)
f 2|1 (y j | Y1∗j > 0) Pr(Y1∗j > 0)
(12)
0
1
Q
Q
where 0 indicates the product over those observations for which s j = 0, and 1 the product
over those observations for which s j = 1. The function f 2|1 denotes the pdf of Y2∗ , given event
Y1∗ > 0. Its functional form can be derived as follows:
1
∂
(F2 (y) − F(0, y))
1 − F1 (0) ∂ y
1
∂
=
f 2 (y) −
F(0, y)
1 − F1 (0)
∂y
f 2|1 (y | Y1∗ > 0) =
where F1 (0) = Pr(Y1∗ ≤ 0) = Pr(S = 0). Substitution into (12) yields
Y
Y
∂
L=
F1 (0)
f 2 (y) −
F(0, y)
∂y
0
1
Y Y
∂
=
F1
f2 −
F(0, y)
∂y
0
(13)
1
where, for convenience, the index j has been dropped in the first line. Additional simplified
notation appears in the second line of (13): F1 will be used from now on to denote F1 (0) =
c Royal Economic Society 2003
109
Modelling sample selection
Pr(Y1∗j ≤ 0) = Pr(S j = 0), as too, from now on F2 denotes F2 (y j ) = Pr(Y2∗j ≤ y j ), and f 2
denotes f 2 (y j ).
The component of (13) that is the most difficult to evaluate is ∂∂y F(0, y). However, should
Y1∗ and Y2∗ be independent, for example, then ∂∂y F(0, y) = F1 f 2 , and L can be separated as per
Q
Q
Q
0 F1
1 (1 − F1 ) ×
1 f 2 . The likelihood (13) is the general form for the self-selection
model. Particular likelihood functions arise from specifications assumed for F etc, a number of
which are examined in the following.
3.2. The Normal model
By far and away the most common specification for F seen in the literature is due to Heckman
(1974), in which bivariate normality, along with univariate normal margins for Y1∗ and Y2∗ are
modelled such that E[Yi∗ ] = xi0 βi and V ar (Yi∗ ) = σi2 , i = 1, 2. That is,
F(y1∗ , y2∗ )
= 82
y1∗
−
x10 β1 ,
y2∗ − x20 β2
;θ
σ
(14)
where σ = σ2 , and σ1 is normalized to unity as all scale information about Y1∗ is lost in the
transformation to S. This self-selection model is termed here the Normal model. A number of
empirical applications of the Normal model are discussed in Amemiya (1985, Section 10.7). The
likelihood is given by
Y
Y 1 y − x 0 β2 x 0 β1 + θ (y − x 0 β2 )/σ 2
2
φ
8 1
L=
8(x10 β1 )
√
2
σ
σ
1
−
θ
0
1
cf. Amemiya (1985, equation 10.7.6).
3.3. Modelling using the copula approach
By using a copula approach, models are constructed that can be viewed as generalizations of the
Normal model, because despite structure being imposed on the joint cdf F through the choice of
copula Cθ , there is no behaviour assumed on the part of the margins, both of which may then be
modelled as desired, subject to parameter identification considerations. Generally, the parameters
of self-selection models that are built using a copula approach are identified through functional
form assumptions, rather than by exclusion restrictions applied to covariates.
Although there are any number of copula families that may be specified, two in particular (the
bivariate normal and the FGM) are included here for they have already appeared in the literature
on modelling self-selection. In all cases, once the margins F1 (y1∗ ) and F2 (y2∗ ) are specified, it
is straightforward to derive the score function, and then to evaluate it and the log-likelihood for
purposes of ML estimation using a quasi-Newton algorithm.
3.3.1. Lee’s model.
Lee (1983) (see also Maddala (1983, Section 9.4)) gives a bivariate normal
specification for the joint cdf F which allows the practitioner to specify non-normal margins.
Lee’s model sets
(15)
F(y1∗ , y2∗ ) = 82 (8−1 (F1 (y1∗ )), 8−1 (F2 (y2∗ )); θ ).
c Royal Economic Society 2003
110
Murray D. Smith
In fact, the copula representation of Lee’s specification shows that the family of Bivariate Normal
copulas (6) is in use here. The sense in which Lee’s model generalizes the Normal model is that
the latter is obtained as the special case corresponding to assuming normality for both margins;
that is, setting F1 (y1∗ ) = 8(y1∗ − x10 β1 ) and F2 (y2∗ ) = 8((y2∗ − x20 β2 )/σ ) in (15) yields (14). The
likelihood of Lee’s model is
p
Y Y
L=
F1 (1 − 8 (8−1 (F1 ) − θ 8−1 (F2 ))/ 1 − θ 2 ) f 2 .
0
1
3.3.2. The FGM model.
Set
F(y1∗ , y2∗ )
= F1 (y1∗ )F2 (y2∗ )(1 + θ (1 − F1 (y1∗ ))(1 − F2 (y2∗ ))).
Clearly, the family of FGM copulas (7) is specified here. The FGM family has been used in
Smith (2002) in the context of the double-hurdle selection model (see Cragg (1971)). Prieger
(2002) advocates the FGM model when modelling self-selection. While the FGM family has the
advantage of mathematical simplicity, its usefulness in modelling data (in general) is curtailed
by its limited coverage of dependency (Joe (1997, p. 149); −2/9 ≤ τ ≤ 2/9, see Section 2.3
above). In this respect, for the purposes of modelling it may be useful to consider extensions to
the FGM family of copulas that expand its coverage; Mari and Kotz (2001, Section 5.7) describe
a number of these. The likelihood of the FGM model is
Y Y
L=
F1 (1 − F1 )(1 − θ F1 (1 − 2F2 )) f 2 .
0
1
3.3.3. The Archimedean class of copula models.
In this subsection, attention focuses on selecting families of copulas from the Archimedean class. Due to the mathematical structure of Archimedean copulas, captured by the generator ϕ, it should not be surprising to learn that the likelihood and score can be re-expressed in terms of (derivatives of) the generator.
For Archimedean copulas, the following derivative, appearing in the general form of the
likelihood (13), simplifies to
∂
∂ F2
∂
F(0, y) =
Cθ (F1 , v)
×
∂y
∂v
∂y
v→F2
ϕ 0 (F2 )
= 0
× f2
ϕ (Cθ )
(16)
where Cθ denotes Cθ (F1 , F2 ) = Cθ (F1 (0), F2 (y)), which is evaluated as ϕ −1 (ϕ(F1 ) + ϕ(F2 )).
The second line of (16) follows from (11). The likelihood function of the self-selection model
for any distribution whose copula is Archimedean is
Y Y
ϕ 0 (F2 )
L=
F1
1− 0
f2.
(17)
ϕ (Cθ )
0
1
ϕ 0 (t)
As the functional form of
is generally quite easy to derive, the likelihood is relatively easy
to code. For example, under the Clayton family (10), the likelihood is
θ+1 !
Y Y
Cθ
F1
1−
f2.
F2
0
1
In Table 2, expressions for the component (1 − ϕ 0 (F2 )/ϕ 0 (Cθ )) of the likelihood are given for
selected families of Archimedean copulas.
c Royal Economic Society 2003
Modelling sample selection
111
0 (F )
2
Table 2. Expressions for 1 − ϕϕ0 (C
.
θ)
AMH
Clayton
Frank
Gumbel
Joe
(1−θ )F1 +θ F12
(1−θ (1−F1 )(1−F2 ))2
1+θ
−(θ+1) −θ
1 − F2
(F1 + F2−θ − 1)− θ
eθ F2 (eθ F1 −eθ )
eθ (F1 +F2 ) +eθ (1−eθ F1 −eθ F2 )
1 − Cθ (F1 , F2 )((−log F1 )θ + (−log F2 )θ )−1+1/θ (− log F2 )θ−1 F2−1
θ
θ +1 θ
θ
θ θ
1 − (1 − F 1 )F 2 (F 1 + F 2 − F 1 F 2 )−1+1/θ
1−
Notes: F 1 = 1 − F1 and F 2 = 1 − F2 .
3.4. Remarks
Under the copula approach, models are constructed in a component-wise fashion: specifying F1 ,
F2 and Cθ . For the margins F1 and F2 , parametric models can be constructed using generalized
linear methods (e.g. McCullagh and Nelder (1989)). This flexibility is a distinct advantage of
the copula approach, as the margins need not be restricted to the same family of distributions.
However, other approaches are also possible; for example, using semi- and non-parametric methods to specify the margins. For the copula function, this article advocates selecting families of
copulas from the Archimedean class.
Given the relatively simple functional form for the self-selection likelihood function under
an Archimedean copula (17), ML estimation can be employed to jointly estimate all parameters.
As general analytical expressions for the score function can be derived (these involve derivatives
of the generator ϕ; see the Appendix for details), it is relatively easy to implement well-known
quasi-Newton optimization algorithms such as DFP and BFGS; the latter is used in the following. Accordingly, the use of an Archimedean copula for Cθ satisfies the need identified by Vella
(1998, p. 132) to maintain ease of implementation as the model assumption departs from bivariate
normality, while remaining in the framework of ML estimation. Unfortunately, obtaining the analytic form of the Hessian of the log-likelihood is a tedious exercise, so if implementation of the
Newton–Raphson algorithm is desired, then, when deriving the Hessian matrix, it is perhaps better to use numerical methods that can approximate derivatives. These considerations also impact
on estimation of the asymptotic variance–covariance matrix of the ML estimator. The method
adopted here is to use as the estimate the final iterate of the approximation to the inverse Hessian
that is generated at each step of the BFGS algorithm. Other variance–covariance matrix estimators include the OPG estimator, although this is known to be prone to inflate standard errors in
small samples. Estimation using the inverse Information matrix does not seem practicable here
due to the difficulties induced by non-linearity in the variables of the model.
It seems quite plausible that the usual suite of asymptotic properties of the ML estimator
will hold. However, it remains an open question for research to prove those regularity conditions
under which the ML estimator is consistent, asymptotically normal and efficient for the selfselection model under an Archimedean copula (or more generally for any copula). A proof might
follow the general approach of Amemiya (1973) (he examined the properties of the ML estimator
in the Tobit model), which was extended by Newey and McFadden (1994) to a number of other
estimators in other models. It is well known that the ML estimator in the Normal model (14) is
sensitive to departures from bivariate normality. It follows then that non-normal selection models
will most likely be sensitive to distributional misspecification error too.
c Royal Economic Society 2003
112
Murray D. Smith
The use of ML contrasts against various two-step estimation methods that have been discussed in the copula literature. For example, Joe (1997, Ch. 10) proposes the IFM method (Inference Functions for Margins), and Bouy´e et al. (2000) (see also Genest et al. (1995)) propose
the CML method (Canonical Maximum Likelihood). The IFM method separately maximizes the
likelihoods of the marginal models, then proceeds by combining the estimated margins into a
multivariate model in order to estimate the remaining parameters, these being the parameters
of the copula. The CML method reverses this procedure, first estimating the association parameters using the empirical distribution functions of the margins, after which the parameters of
the margins are estimated. Generally, these estimators are consistent and asymptotically normal,
although less efficient than ML (e.g. see Joe and Xu (1996)); their advantage over ML is primarily in computational ease. However, in the specific case of the self-selection model, neither
estimator is appropriate because the model fitted for F2 only uses those observations pertaining
to the self-selected sub-population, thereby inducing selectivity bias.
Given empirical data, model selection across differing self-selection specifications is an
a posteriori consideration, for it is rare that the true data generating mechanism F is known
a priori. Setting aside for now the specification of the margins F1 and F2 , differing families of
copulas Cθ are, in general, parametrically non-nested, even if the families being compared are
Archimedean. For example, even though the same symbol θ is used to denote the association
parameter in each family in Table 1, none of the families that are listed there parametrically nests
another in that list. Consequently, following the suggestion of Joe (1997, Section 10.3), information measures such as AIC and BIC applied to each fitted model can be used as the selection
criterion amongst competing models. This is the method adopted in the examples which follow. However, because in both examples the specifications of the margins F1 and F2 are fixed
across competing models (i.e. models compete only according to specifications for Cθ , and so
the number of parameters does not vary across models), then model selection procedures that
use information measures (like AIC and BIC) that penalize fit by the number of parameters
used to attain that fit is equivalent simply to selection based on the largest of the maximized
log-likelihoods.
4. APPLICATIONS
4.1. Example 1: labour supply
In this example, self-selection models for female labour supply are constructed and estimated
using the specifications discussed in Section 3. The data (n = 200) were randomly drawn from
the 1987 Michigan Panel Study of Income Dynamics (these data are tabulated in Lee (1996,
Appendix)). The variable descriptions used here correspond to his:
Symbol
Y
inc
edu
pkid
mort
1
Description
Wife labour supply (hours per month)
Household income ($000)
Wife schooling (years)
Number of pre-school children, age 0 to 5 years
0-1 dummy, equal to 1 if house is mortgaged
Constant dummy
Here, the covariates of the binary indicator of labour force participation S are specified to be
x1 = (edu, pkid, mort, 1), while the covariates of labour supply Y are specified to be x2 =
c Royal Economic Society 2003
113
Modelling sample selection
Table 3. ML estimates of θ and τ for labour supply; fixed normal–normal margins.
θ
Indep.
(1)
0.000
τ
log L
Normal
(2)
FGM
(3)
0.584
Clayton
(5)
0.280
[0.445]
[1.684]
2.757
1.000
0.222
0.155
0.123
0.286
0.000
0.498
−933.012
−933.310
−933.761
−932.845
−933.959
−931.841
0.461
1.000
0.000
0.305
−933.959
−933.640
[0.289]
{1.47}
AMH
(4)
[0.323]
{1.47}
Frank
(6)
{0.72}
Gumbel
(7)
{1.88}
Joe
(8)
2.841
[0.734]
{5.19}
Notes: (i) Estimated standard errors on b
θ appear within square braces [ ].
(ii) b
τ = τ (b
θ ). Appearing in curly braces { } are associated t-statistics for the test of independence: τ = 0. These are
derived using the delta theorem.
(iii) For the bivariate normal distribution: τ (θ ) = 2π −1 sin−1 (θ ).
(iv) For the FGM distribution: τ (θ) = 2θ/9.
R
(v) For Archimedean copulas: τ (θ) = 1 + 4 01 ϕϕ(t)
0 (t) dt.
(inc, pkid, 1). Note that 44 respondents report 0 hours of labour. It is worth noting that Lee’s
analyses of these data do not find significant evidence of association between participation and
supply; in other words, for these data, he finds that selectivity bias is insignificant.
Following Lee, both margins are assumed normally distributed: Y1∗ ∼ N (x10 β1 , 1) and Y2∗ ∼
N (x20 β2 , σ 2 ) – term this ‘normal–normal’ margins. Then,
F1 =
1 − 8(x10 β1 )
and
thus,
f2 =
1
φ
σ
F2 = 8
y − x20 β2
σ
y − x20 β2
σ
.
For various families of copulas, ML estimation results appear in Table 3. Point estimates of the
covariate parameters are suppressed for there is broad similarity in these estimates across each
of the models. This is to be expected as the margins are fixed. However, there is improvement
in efficiency (smaller estimated standard errors) of the covariate parameter estimates, especially
so for the preferred Joe model over the others. A complete table of ML estimation results is
available from the author upon request.
For the Independent model (column (1)), Y1∗ and Y2∗ are specified to be independent (i.e.
F(y1∗ , y2∗ ) = F1 (y1∗ )F2 (y2∗ )) and so the association parameter θ is fixed at 0. In column (2),
results for the Normal model appear. There is a small improvement in the value of the loglikelihood in the Normal model from that of the Independent model, but at conventional levels of
significance this improvement is insignificant, indicating that selectivity bias is not present under
this specification. For the FGM model, maximization of the likelihood requires the degenerate
setting θ = 1 at the boundary of the parameter space for these data. The results for the FGM
model (column (3)) reinforce the opinion expressed in Section 3.3.2 concerning the inadequacy
of the FGM copula to model empirical data.
Results for models that use Archimedean copulas appear in columns (4)–(8). The Gumbel
model performs the worst for these data, because to maximize the likelihood the degenerate unit
estimate of θ corresponds to independence. The AMH and Clayton models do not perform well,
neither estimate of θ is significant from 0 (independence corresponds to θ = 0 for the AMH
family, and θ → 0+ for the Clayton family), and both maximized log-likelihoods fail to improve
c Royal Economic Society 2003
114
Murray D. Smith
on that achieved by the (degenerate) FGM model. Similar to the results for most of the other
models, Frank’s model (column (7)) yields insignificant positive association between Y1∗ and Y2∗
for these data. This is, however, not the case if Joe’s family of copulas are used, for the estimate
of θ of 2.841 in Joe’s model (column (8)) is significantly different from unity (θ = 1 yields
independence under Joe’s family), the relevant t-statistic being 2.5. Joe’s model also outperforms
the others presented here in the sense that the maximized log-likelihood of −931.841 is greatest.
As the association parameter θ is not comparable across the families of copulas appearing in
Table 3, it is re-parameterized to Kendall’s τ . The ML estimate of τ and the associated t-statistic
for the test of selectivity bias (τ = 0) appear in Table 3. Of all the models considered, the
estimate of τ of 0.498 for Joe’s model is greatest, as too, with an associated t-statistic of 5.19, it
is the only model whose estimate differs significantly from zero. Under the preferred Joe model,
there is significant evidence in these data for the presence of selectivity.
4.2. Example 2: length of time in hospital
Prieger (2002) studied the total spell of hospitalization for individuals reporting in the 1996 wave
of the US Medical Expenditure Panel Survey (n = 14,946; these data are available for download
from the Journal of Applied Econometrics Data Archive). Prieger fitted the Independent, Lee and
FGM self-selection models (see Sections 3.3.1–3.3.2), ultimately preferring the outcome of the
latter as per the maximized log-likelihood criterion. In this example, a further modelling improvement is demonstrated by using Archimedean copulas, under the same model selection criterion.
Prieger’s specification of the marginal models is termed here ‘normal-gamma’ margins, arising as follows: (i) Normal. Of the entire sample, a total of 1346 individuals reported having
been admitted to hospital. To represent this, Prieger specified normality for the propensity to
hospitalization; that is, Y1∗ ∼ N (x 0 β1 , 1), thus:
F1 = 1 − 8(x 0 β1 )
where the covariates x are described in Prieger’s Table 4. (ii) Gamma. For all hospitalized individuals (the self-selected sub-population), Prieger assumed that the duration of time spent per visit
to hospital was exponentially distributed with mean 1/λ = exp(x 0 β2 ). For Q = q ∈ {1, 2, 3, . . .}
hospitalizations (some 362 individuals reported multiple hospitalizations), the durations of which
Prieger assumed mutually independent, finds Y , the total spell of hospitalization, such that Y |
(Q = q ≥ 1) ∼ Gamma(q, 1/λ) with pdf
f2 =
1 q
λ exp(−λy)y q−1
0(q)
for real y > 0, and cdf
0(q, λy)
0(q)
R∞
where 0(a, b) denotes the incomplete gamma function, b exp(−t)t a−1 dt.
Prieger’s preferred FGM model yields a negative estimate of dependence (see Table 4).
Accordingly, it would seem appropriate to include families of Archimedean copulas that can
F2 = 1 −
c Royal Economic Society 2003
115
Modelling sample selection
Table 4. ML estimates for length of hospitalization; fixed normal-gamma margins.
θ
Indep.
(1)
0.000
τ
log L
Lee
(2)
FGM
(3)
AMH
(4)
Joe
(5)
AP
(6)
0.0013
−0.8735
−0.8624
[0.023]
1.0102
[0.045]
[0.004]
0.1228
[0.048]
0.000
0.0008
−0.1941
−0.1604
−0.0789
{0.06}
0.0059
{−18.24}
{−22.49}
{2.38}
{−3.14}
−7674.25
−7674.25
−7641.42
−7641.64
−7670.14
−7613.61
[0.016]
Notes: (i) Estimated standard errors on b
θ appear within square braces [ ].
(ii) b
τ = τ (b
θ ). Appearing in curly braces { } are associated t-statistics for the test of independence: τ = 0. These are
derived using the delta theorem.
R∞ R∞
(iii) For the Bivariate Normal copula: τ (θ ) = 4 −∞
−∞ 82 (x, y; θ )φ2 (x, y; θ )d xdy − 1.
(iv) For the FGM copula: τ (θ) = 2θ/9.
R
(v) For Archimedean copulas: τ (θ) = 1 + 4 01 ϕϕ(t)
0 (t) dt.
accommodate negative dependence in order to model these data.1 One family of Archimedean
copulas that can accommodate negative dependence (in fact it attains W , the lower Fr´echet bound
for copulas, as θ → 0+ ) is the AP family of copulas
√
Cθ (u, v) = 12 (r + r 2 + 4θ )
(18)
− 1 , and θ > 0 (see Table 1). The generator is ϕ(t) =
p
(1 + θ/t)(1 − t), for which
= 12 (1 − θ − t + (1 − θ − t)2 + 4θ) is convex, but not
completely monotonic. Note the similarity in appearance of the AP family to the Plackett family
of copulas (8).
For various families of copulas, ML estimation results appear in Table 4. For the same reasons
as given earlier, point estimates of the covariate parameters are suppressed (a complete table of
ML estimation results is available upon request). Fortunately, there is close agreement between
Prieger’s point estimates of (β1 , β2 , θ) and the complete set of results corresponding to columns
(1)–(3) of Table 4. However, where numerical differences arise they are in the estimated standard errors. This is because Prieger used the OPG method to estimate the asymptotic variance–
covariance matrix.
Columns (4)–(6) of Table 4 list estimation results for the association parameter θ and for
Kendall’s τ = τ (θ). The performance of the AMH model almost mimics that of the FGM model
for these data, both estimate significant negative dependence—for the AMH model b
τ = −0.1604
(t-statistic −22.49 for τ = 0) and for the FGM model b
τ = −0.1941 (t-statistic −18.24 for
τ = 0)—indicating the presence of self-selection. The Joe model, preferred in Example 1, performs poorly in this case, barely managing to improve upon the Independent and Lee models,
where r = u + v − 1 − θ
1
1
u + v
ϕ −1 (t)
1 The existence of any such family has been questioned by Jouini and Clemen, they write: ‘. . . Archimedean copulas
can be used to model only positive dependence . . . ’ (Jouini and Clemen (1996, p. 446)). Their view is due to a theorem (see Jouini and Clemen (1996, Theorem 10)) in which they prove that an Archimedean copula (for two or more
dimensions) with strict generator ϕ, such that ϕ −1 is completely monotonic, is bounded below by the Product copula
(complete monotonicity implies that for t ∈ [0, ∞) and all θ , all derivatives of ϕ −1 must exist and alternate in sign,
viz. (−1)k ∂ k ϕ −1 (t)/∂t k ≥ 0 for k = 0, 1, 2, 3, . . .). In the bivariate case, Jouini and Clemen’s view is incorrect. A
bivariate copula can be Archimedean under the weaker condition that ϕ −1 is convex ((Schweizer, 1991, Theorem 3.2);
convexity requires (−1)k ∂ k ϕ −1 (t)/∂t k ≥ 0 for k = 0, 1, 2, and leaves free the sign of the higher derivatives). Indeed,
the Frank family is Archimedean (see Table 1; Genest (1985)) with ϕ −1 (t) = −θ −1 log(1 + e−s (e−θ − 1)) convex, but
not completely monotonic, where this family is comprehensive.
c Royal Economic Society 2003
116
Murray D. Smith
both of which Prieger dismissed. The explanation for the poor performance of Joe’s model in
this example lies in the inability of the Joe family to represent negative dependence (ϕ −1 (t) =
1 − (1 − e−t )1/θ is completely monotonic, hence range 0 ≤ τ < 1 as per Jouini and Clemen’s
theorem). Finally, the AP model can be seen to outperform the others for these data, with the
maximized value of the log-likelihood of −7613.61 well above that obtained by Prieger’s preferred FGM model. The estimate b
τ = −0.0789 is significantly negative (t-statistic −3.14 for
τ = 0), indicating the presence of self-selection in these data.
To further contrast the models consider, for example, estimation of the mean duration of total
hospitalization, given that the individual is admitted. For Archimedean models
Z ∞
∗
E[Y | Y1 > 0] =
y f 2|1 (y | Y1∗ > 0)dy
0
Z ∞
1
q
ϕ 0 (F2 )
=
−
y 0
f 2 dy .
1 − F1 λ
ϕ (Cθ )
0
For only one visit to hospital (q = 1) and at x = x (x collects the covariate averages across the
1346 hospitalized individuals), this evaluates to 3.74 days for the AP model. For other, worsefitting models, estimates are 3.97 days for the AMH model, and 3.95 days for the FGM model. If
the selectivity in these data is ignored, the mean duration estimated by the Independence model
is considerably larger at 4.43 days.
5. EXTENSIONS
In this section, brief explanations of the derivation of the likelihoods of the switching regimes
model and the double-selection model are given, where it is assumed that the copulas representing the joint cdfs are Archimedean. In both instances, derivation is based on the existence of a
trio of latent utilitarian variables (Y1∗ , Y2∗ , Y3∗ ), the margins of which have cdf and pdf denoted
respectively by Fi (yi∗ ) and f i (yi∗ ), for yi∗ ∈ R (i = 1, 2, 3). It is assumed that these margins
depend on covariates and parameters; however, their specification is not of concern here.
5.1. The switching regimes model
The switching regimes model (also referred to as the extended or utility-based Roy model of
selectivity) arises when observations on the trio of random variables (S, Y2 , Y3 ) are generated
according to the following observation rules:
S = 1{Y1∗ > 0},
Y2 = 1{Y1∗ > 0}Y2∗ ,
Y3 = 1{Y1∗ ≤ 0}Y3∗ .
Basically, Y2∗ is observed when Y1∗ > 0, otherwise it is Y3∗ that is observed; the switching mechanism S is binary. Note that dummy values of 0 are assigned to Y2 and Y3 as required, according
to the outcomes of the switch S. Here, Fi (yi∗ ) is assumed continuous throughout the support of
Yi∗ , for i = 2, 3. Vijverberg (1993) cites a number of applications of this model.
Suppose that data (s j , y2 j , y3 j ) denotes the jth observation on (S, Y2 , Y3 ), j = 1, . . . , n. For
a random sample of size n, the likelihood is given by
c Royal Economic Society 2003
117
Modelling sample selection
L=
YZ
0
=
Y
0
−∞
f 13 (y1∗ j , y3 j )dy1∗ j
f 3|1 (y3 j |
1
Y1∗j
≤
0
∞
YZ
0) Pr(Y1∗j
0
≤ 0)
f 12 (y1∗ j , y2 j )dy1∗ j
Y
f 2|1 (y2 j | Y1∗j > 0) Pr(Y1∗j > 0)
1
Y
Y ∂
∂
F13 (0, y3 )
F12 (0, y2 ) ,
=
f2 −
∂ y3
∂ y2
0
(19)
1
where F12 and F13 denote bivariate margins with respective pdfs f 12 and f 13 , and f 2|1 and f 3|1
denote univariate pdfs conditioned on the event shown involving Y1∗ . The first line of (19) is the
equivalent of Amemiya’s formula for L (see Amemiya (1985, equation (10.10.2))), requiring that
Y1∗ is continuous. The second line expresses the likelihood in terms of the binary switch, similar
to (12), and it is more general than the expression given in the previous line in that Y1∗ need not
be continuous. The third line expresses the likelihood in terms of the underlying margins, by
analogy with (13); the presence of the differentials is due to the continuity assumptions on Y2∗
and Y3∗ .
From the general form of the likelihood (19), it is clear that any association parameters that
may exist between Y2∗ and Y3∗ cannot be identified as L is not a function of these parameters
(L does not depend on the bivariate margin F23 nor on the trivariate F); for further discussion,
see Heckman and Honor´e (1990). This implies that it is superfluous to specify F, the trivariate
distribution of (Y1∗ , Y2∗ , Y3∗ ).
Under the copula approach, modelling a switching regimes process proceeds by specifying
margins Fi , and the copulas that represent the bivariate margins F12 and F13 . Let ϕ and η denote
respectively the generators of the (Archimedean) copulas that represent F12 and F13 . Then, the
likelihood is given by
!
Y
Y η0 (F3 )
ϕ 0 (F2 )
f3
1−
f2
L=
ϕ 0 (Cθ12 )
η0 (Cλ13 )
1
0
where Cθ12 = ϕ −1 (ϕ(F1 (0)) + ϕ(F2 (y2 ))) and Cλ13 = η−1 (η(F1 (0)) + η(F3 (y3 ))), and θ and λ
collect the relevant association parameters. It is not necessary that the generators ϕ and η have
the same functional form, but this can be imposed. For given specifications of the margins Fi
and generators ϕ and η, it is easy to construct the likelihood by adapting the quantities given in
Table 2.
5.2. The double-selection model
The double-selection model arises when observations on a trio of random variables (S1 , S2 , Y )
are generated according to the following observation rules:
S1 = 1{Y1∗ > 0}
S2 = 1{Y1∗ > 0, Y2∗ > 0}
Y = 1{Y1∗ > 0, Y2∗ > 0}Y3∗ .
In this model, the two binary selectors S1 and S2 serve to partition the total sample; note that S1 is
determined in sequence prior to S2 . Figure 2 depicts the sample space of outcomes of (S1 , S2 , Y )
as the branches of a decision tree.
Tunali (1986) cites a number of applications of the double-selection model. A recent example is given by Henneberger and Sousa-Poza (1998), whose double-selection model is designed
c Royal Economic Society 2003
118
Murray D. Smith
S1= 1
S1= 0
(0, 0, 0)
S2= 0
S2=1
(1,1,Y)
(1, 0, 0)
Figure 2. Decision tree of outcomes of (S1 , S2 , Y ).
to account for survey non-response: S1 is used to indicate labour force participation, and S2 to
indicate whether or not participants report earnings; those electing to do so report wage earnings Y .
Let si1 , . . . , sin denote n observations on Si (si j ∈ {0, 1}, i = 1, 2, j = 1, . . . , n), and
y1 , . . . , yn the corresponding n observations on Y (y j ∈ R, j = 1, . . . , n). For a random sample
of n observations, the likelihood function for the double-selection model is given by
L=
Y
Pr(Y1∗j ≤ 0)
0
×
Y
Pr(Y2∗j ≤ 0 | Y1∗j > 0) Pr(Y1∗j > 0)
1
Y
f 3|12 (y j | Y1∗j > 0, Y2∗j > 0) Pr(Y1∗j > 0, Y2∗j > 0),
2
Q
Q
where 0 indicates the product over those observations
Q for which s1 = 0, 1 the product over
those observations for which s1 = 1 and s2 = 0, and 2 the product over those observations for
which s1 = s2 = 1. Here
1 ∂
(F3 (y) − F13 (0, y) − F23 (0, y) + F(0, 0, y))
p ∂y
1
∂
∂
∂
=
f 3 (y) −
F13 (0, y) −
F23 (0, y) +
F(0, 0, y) ,
p
∂y
∂y
∂y
f 3|12 (y | Y1∗ > 0, Y2∗ > 0) =
where p = Pr(Y1∗ > 0, Y2∗ > 0); obviously Y3∗ is required to be a continuous random variable.
Substitution then yields
c Royal Economic Society 2003
119
Modelling sample selection
L=
Y
F1 (0)
0
×
Y
(F2 (0) − F12 (0, 0))
1
Y
2
∂
∂
∂
f 3 (y) −
F13 (0, y) −
F23 (0, y) +
F(0, 0, y)
∂y
∂y
∂y
(20)
as the general form of the likelihood.
Let the 3-copula representation of the joint cdf of (Y1∗ , Y2∗ , Y3∗ ) be as follows:
F(y1∗ , y2∗ , y3∗ ) = Cθ (F1 (y1∗ ), F2 (y2∗ ), F3 (y3∗ ))
and assume that Cθ is a three-part family of Archimedean copulas, with additive generator ϕ; in
other words, Cθ is specified such that
ϕ(Cθ (u, v, w)) = ϕ(u) + ϕ(v) + ϕ(w)
for all real (u, v, w) ∈ I3 . Moreover, because the dimensionality in this case is greater than 2, the
inverse function ϕ −1 must be continuous on [0, ∞) and be completely monotonic (see Nelsen
(1999, Section 4.6)). An example of a family of 3-copulas is (u −θ + v −θ + w−θ − 2)−1/θ , θ > 0,
termed the Clayton 3-copula. As the bivariate margins of F are themselves Archimedean with
generator ϕ, then the derivatives appearing in (20) simplify to;
ϕ 0 (F3 (y))
∂
Fi3 (0, y) = 0
f 3 (y)
∂y
ϕ (Fi3 (0, y))
∂
ϕ 0 (F3 (y))
F(0, 0, y) = 0
f 3 (y).
∂y
ϕ (F(0, 0, y))
(i = 1, 2)
Substitution into (20) yields
Y
Y
L=
F1 (0) (F2 (0) − F12 (0, 0))
0
1
Y
×
1−
2
ϕ 0 (F3 (y))
ϕ 0 (F3 (y))
ϕ 0 (F3 (y))
−
+
ϕ 0 (F13 (0, y)) ϕ 0 (F23 (0, y)) ϕ 0 (F(0, 0, y))
f 3 (y).
(21)
Observe that the bivariate and trivariate cdfs appearing as the arguments of ϕ 0 in (21) only ever
require univariate integration in order to be evaluated, as per
Fi3 (0, y) = ϕ −1 (ϕ(Fi (0)) + ϕ(F3 (y)))
(i = 1, 2)
and
F(0, 0, y) = ϕ −1 (ϕ(F1 (0)) + ϕ(F2 (0)) + ϕ(F3 (y))).
Thus, computation of the likelihood under an Archimedean copula is straightforward. In contrast,
if F123 is assumed trivariate normal, evaluating the likelihood requires greater numerical effort:
Fi3 (0, y) requires at least one numerical integration, and for F(0, 0, y) at least two are required.
Comparing the likelihoods of the self-selection model (17) and its extension to the doubleselection model (21), suggests that a similar pattern of terms will arise if further numbers of
(sequential) binary selection mechanisms happen to be present in the data, provided, of course,
that model specification assumes the joint cdf can be represented by an Archimedean copula. The
c Royal Economic Society 2003
120
Murray D. Smith
likelihood will then have a number of terms involving a ratio of derivatives of the generator, with
all the marginal cdfs (of whatever dimension) calculable with only univariate integration. In these
higher dimensional models (the triple-selection model etc), the specification of Archimedean
copulas will still allow ML estimation to proceed using standard iterative algorithms. This then
neatly avoids the need for higher dimensional numerical integration, or for estimation based on
simulation methods.
6. CONCLUSION
In this article, a copula approach was used in the specification of binary models that are designed
to account for data selectivity. This involved specifying distributions for each of the margins, as
well as selecting a family of copulas. It was shown that previous modelling attempts that have
appeared in the selectivity literature (notably Lee (1983)) corresponded to the use of particular
families of copulas. When selecting copulas, the class of Archimedean copulas was, in particular,
shown to have a number of attractive properties. Not least among these was the simple form taken
by the likelihood, which was shown to involve a ratio of derivatives of the generator function.
ACKNOWLEDGEMENTS
This paper was written while visiting the Payments Policy Department of the Reserve Bank of
Australia and the Institute for Economics and Social Statistics of the University of Dortmund,
Germany. Access to the facilities of the Bank and the University of Dortmund are gratefully
acknowledged. In addition, financial assistance from the Alexander von Humboldt Foundation
is acknowledged gratefully. Thanks are also due to the co-Editor Pravin Trivedi as well as the
anonymous referees for a number of helpful comments. Others providing helpful comments and
suggestions include Walter Kr¨amer, Christian Kleiber, Jerry Hausman and seminar participants
at the universities of Melbourne, Dortmund, Amsterdam, Zurich and Munich. Any remaining
errors are entirely my responsibility.
REFERENCES
Amemiya, T. (1973). Regression analysis when the dependent variable is truncated normal. Econometrica
41, 997–1016.
Amemiya, T. (1985). Advanced Econometrics. Cambridge, MA: Harvard.
Bouy´e, E., V. Durrleman, A. Nikeghbali, G. Riboulet and T. Roncalli (2000). Copulas for finance: a reading
guide and some applications, All About Value at Risk Working Papers (download from http://www.
gloriamundi.org/var/wps.html).
Clemen, R. T. and T. Reilly (1999). Correlations and copulas for decision and risk analysis. Management
Science 45, 208–24.
Cragg, J. G. (1971). Some statistical models for limited dependent variables with applications to the demand
for durable goods. Econometrica 39, 829–44.
Dall’Aglio, G. (1991). Frechet classes: the beginnings. In G. Dall’Aglio, S. Kotz and G. Salinetti (eds),
Advances in Probability Distributions with Given Marginals: Beyond the Copulas, Chapter 1, pp. 13–50.
Dordrecht: Kluwer.
c Royal Economic Society 2003
Modelling sample selection
121
Dardanoni, V. and P. Lambert (2001). Horizontal inequity comparisons. Social Choice and Welfare 18,
799–816.
Fisher, N. I. (1997). Copulas. In S. Kotz, C. B. Read and D. L. Banks (eds), Encyclopedia of Statistical
Sciences, Update vol. 1, pp. 159–63. New York: Wiley.
Galambos, J. (1978). The Asymptotic Theory of Extreme Order Statistics. New York: Wiley.
Genest, C. (1985). Frank’s family of bivariate distributions. Biometrika 74, 549–55.
Genest, C., K. Ghoudi and L.-P. Rivest (1995). A semiparametric estimation procedure of dependence parameters in multivariate families of distributions. Biometrika 82, 542–52.
Genest, C. and J. MacKay (1986). The joy of copulas: bivariate distributions with uniform marginals. American Statistician 40, 280–3.
Genest, C. and L.-P. Rivet (1993). Statistical inference procedures for bivariate Archimedean copulas. Journal of the American Statistical Association 88, 1034–43.
H¨ardle, W. and C. F. Manski (eds.) (1993). Nonparametric and semiparametric approaches to discrete response analysis. Annals of the Journal of Econometrics 58, 1–274.
Heckman, J. J. (1974). Shadow prices, market wages and labor supply. Econometrica 42, 679–94.
Heckman, J. J. and B. E. Honor´e (1990). The empirical content of the Roy model. Econometrica 58,
1121–49.
Henessey, D. A. and H. E. Lapan (2002). The use of Archimedean copulas to model portfolio allocations.
Mathematical Finance 12, 143–54.
Henneberger, F. and A. Sousa-Poza (1998). Estimating wage functions and wage discrimination using data
from the 1995 Swiss labour force survey: a double-selectivity approach. International Journal of Manpower 19, 486–506.
Joe, H. (1997). Multivariate Models and Dependence Concepts. London: Chapman and Hall.
Joe, H. and J. J. Xu. (1996). The estimation method of inference functions for margins for multivariate
models, Technical Report no. 166, Department of Statistics, University of British Columbia (download
from http://hajek.stat.ubc.ca/~harry/ifm.pdf).
Jouini, M. N. and R. T. Clemen (1996). Copula models for aggregating expert opinions. Operations
Research 44, 444–57.
Kimeldorf, G. and A. R. Sampson (1975). Uniform representations of bivariate distributions. Communications in Statistics, Theory and Method 4, 617–27.
Kwerel, S. M. (1983). Fr´echet Bounds. In S. Kotz and N. L. Johnson (eds), Encyclopedia of Statistical
Sciences, vol. 3, pp. 202–9. New York: Wiley.
Lee, L.-F. (1983). Generalized econometric models with selectivity. Econometrica 51, 507–12.
Lee, M.-J. (1996). Methods of Moments and Semiparametric Econometrics for Limited Dependent Variable
Models. New York: Springer.
Maddala, G. S. (1983). Limited-Dependent and Qualitative Variables in Econometrics. Cambridge: Cambridge University Press.
Maddala, G. S. (ed.) (1994). Econometric Methods and Applications, vol. 2. Aldershot: Edward Elgar.
Mari, D. D. and S. Kotz (2001). Correlation and Dependence. London: Imperial College Press.
McCullagh, P. and J. A. Nelder (1989). Generalized Linear Models, 2nd edn. London: Chapman and Hall.
Nelsen, R. B. (1999). An Introduction to Copulas. New York: Springer.
Newey, W. K. and D. L. McFadden (1994). Large sample estimation and hypothesis testing. In R. F. Engle
and D. L. McFadden (eds), Handbook of Econometrics, Chapter 36, vol. 4. New York: North-Holland.
Patton, A. J. (2001). Modelling time-varying exchange rate dependence using the conditional copula,
Department of Economics Discussion Paper 2001-09, San Diego: University of California.
Prieger, J. E. (2002). A flexible parametric selection model for non-normal data with application to health
care usage. Journal of Applied Econometrics 17, 367–92.
c Royal Economic Society 2003
122
Murray D. Smith
Schweizer, B. (1991). Thirty years of copulas. In G. Dall’Aglio, S. Kotz and G. Salinetti (eds), Advances in
Probability Distributions with Given Marginals: Beyond the Copulas, Chapter 2, pp. 13–50. Dordrecht:
Kluwer.
Schweizer, B. and A. Sklar (1983). Probabilistic Metric Spaces. New York: North-Holland.
Smith, M. D. (2002). On specifying double-hurdle models. In A. Ullah, A. Wan and A. Chaturvedi (eds),
Handbook of Applied Econometrics and Statistical Inference, Chapter 25, pp. 535–52. New York:
Marcel-Dekker.
Tunali, I. (1986). A general structure for models of double-selection and an application to a joint migration/earnings process with remigration. Research in Labor Economics 8B, 235–82.
Valdez, E. A. (2001). Copula Models for Sums of Dependent Risks, School of Actuarial Studies,
University of New South Wales (download from http://www.actuarial.unsw.edu.au/events/
symposiums/2001/EValdez.pdf).
Vella, F. (1998). Estimating models with sample selection bias: a survey. The Journal of Human Resources
33, 127–43.
Vijverberg, W. P. M. (1993). Measuring the unidentified parameter of the extended Roy model of selectivity.
Journal of Econometrics 57, 69–90.
APPENDIX: DERIVATION OF THE SELF-SELECTION SCORE
In this section, the score function is derived for the self-selection model under a family of Archimedean
copulas in terms of derivatives of the generator function ϕ. In turn, the score depends on the following
derivatives:
∂ F1
∂ F2
∂ log f 2
∂ F2
∂ log f 2
,
,
,
,
,
∂β1
∂β2
∂β2
∂σ
∂σ
all of which can be determined once a particular functional form is assumed for the margins F1 (y1∗ ) and
F2 (y2∗ ). Moreover, as Cθ depends on all parameters, then, using (11), the following derivatives will be
required when constructing the score vector
ϕ 0 (F ) ∂ F1
∂Cθ
= 0 1
,
∂β1
ϕ (Cθ ) ∂β1
∂Cθ
ϕ 0 (F ) ∂ F2
= 0 2
,
∂β2
ϕ (Cθ ) ∂β2
∂Cθ
ϕ 0 (F ) ∂ F2
= 0 2
.
∂σ
ϕ (Cθ ) ∂σ
From (17), the log-likelihood function for parameter λ = (β1 , β2 , σ, θ) for the self-selection model
under an Archimedean copula is given by
X
X
ϕ 0 (F )
log L =
log F1 +
log f 2 + log 1 − 0 2
,
ϕ (Cθ )
0
1
P
P
where 0 denotes the sum over those observations for which s j = 0 and 1 denotes the sum over those
observations for which s j = 1. The component of the score due to β1 is given by
0
X ∂ log F1 X ∂
ϕ 0 (Cθ )
ϕ (F2 ) 00
∂Cθ
ϕ (Cθ )
log L =
+
∂β1
∂β1
ϕ 0 (Cθ ) − ϕ 0 (F2 ) ϕ 0 (Cθ )2
∂β1
0
1
X 1 ∂ F1 X
∂F
=
+
α1 α2 1 ,
F1 ∂β1
∂β1
1
0
where the scalars α1 and α2 are given by
α1 =
ϕ 0 (Cθ )
0
ϕ (Cθ ) − ϕ 0 (F2 )
and
α2 =
ϕ 0 (F1 )ϕ 0 (F2 )ϕ 00 (Cθ )
.
ϕ 0 (Cθ )3
c Royal Economic Society 2003
123
Modelling sample selection
The component of the score due to β2 is given by
θ
ϕ 0 (Cθ )ϕ 00 (F2 ) ∂∂βF2 − ϕ 0 (F2 )ϕ 00 (Cθ ) ∂C
X ∂ log f 2
∂
∂β
2
2
log L =
− α1
∂β2
∂β2
ϕ 0 (Cθ )2
1
!
!
X ∂ log f 2
ϕ 00 (F2 ) ϕ 0 (F2 )2 ϕ 00 (Cθ ) ∂ F2
=
−
− α1
∂β2
ϕ 0 (Cθ )
∂β2
ϕ 0 (Cθ )3
1
X ∂ log f 2
∂F
=
− α3 2 ,
∂β2
∂β2
1
where the scalar α3 is given by
α3 = α1
!
ϕ 00 (F2 ) ϕ 0 (F2 )2 ϕ 00 (Cθ )
−
.
ϕ 0 (Cθ )
ϕ 0 (Cθ )3
The component of the score due to σ is given by
F2
θ
X ∂ log f 2
ϕ 0 (Cθ )ϕ 00 (F2 ) ∂∂σ
− ϕ 0 (F2 )ϕ 00 (Cθ ) ∂C
∂
∂σ
log L =
− α1
∂σ
∂σ
ϕ 0 (Cθ )2
1
X ∂ log f 2
∂F
=
− α3 2 .
∂σ
∂σ
!!
1
Clearly α1 , α2 and α3 depend on the generator ϕ, as well as every parameter in the model. The component
of the score due to θ has a more complicated form
0 (C )
0 (F )
θ
2
X
ϕ 0 (F2 ) ∂ϕ ∂θ
− ϕ 0 (Cθ ) ∂ϕ∂θ
∂
log L =
α1
∂θ
ϕ 0 (Cθ )2
1
!
X
ϕ 0 (F2 ) ∂ϕ 0 (Cθ ) ϕθ0 (F2 )
=
α1
− 0
,
(22)
ϕ (Cθ )
ϕ 0 (Cθ )2 ∂θ
1
where
ϕθ0 (t) =
∂2
ϕ(t).
∂t∂θ
∂ ϕ 0 (C ) can be difficult to simplify. This is because
In (22), the expression for ∂θ
θ
∂ 0
∂ 0
ϕ (Cθ ) =
ϕ (Cθ (u, v))
∂θ
∂θ
u→F1 ,v→F2
depends on θ through both the function ϕ 0 and the argument supplied to it, Cθ . However, for a given family
∂ ϕ 0 (C (u, v)) can be derived. For
of Archimedean copulas, such as those listed in Table 1, the form of ∂θ
θ
example, for the Clayton family (10)
!
∂ 0
1
θ + 1 v θ log u + u θ log v
−(θ+1)
ϕ (C) = C
− log C .
∂θ
θ
θ
u θ + v θ − (uv)θ
∂ ϕ 0 (C (u, v)) is straightforward if a computer
The task of evaluating the differential forms α1 , α2 , α3 and ∂θ
θ
algebra system such as Mathematica is employed.
c Royal Economic Society 2003











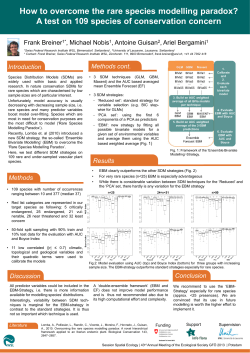





© Copyright 2024